CSVのデータをSentence-Transformersで意味ベクトルに変換する
CSVのデータについてまとめて意味ベクトルを取得したくて調べた備忘録です。
- CSVファイル(import.csv)の「文章」列に短文が入っている
- Pythonで「文章」列のデータを取り込み、各行の文章を意味ベクトルに変換する
- 変換後の意味ベクトルはCSVファイルの各行の「意味ベクトル」列に書き込む
CSV(import.csv)は下記のようなイメージです。
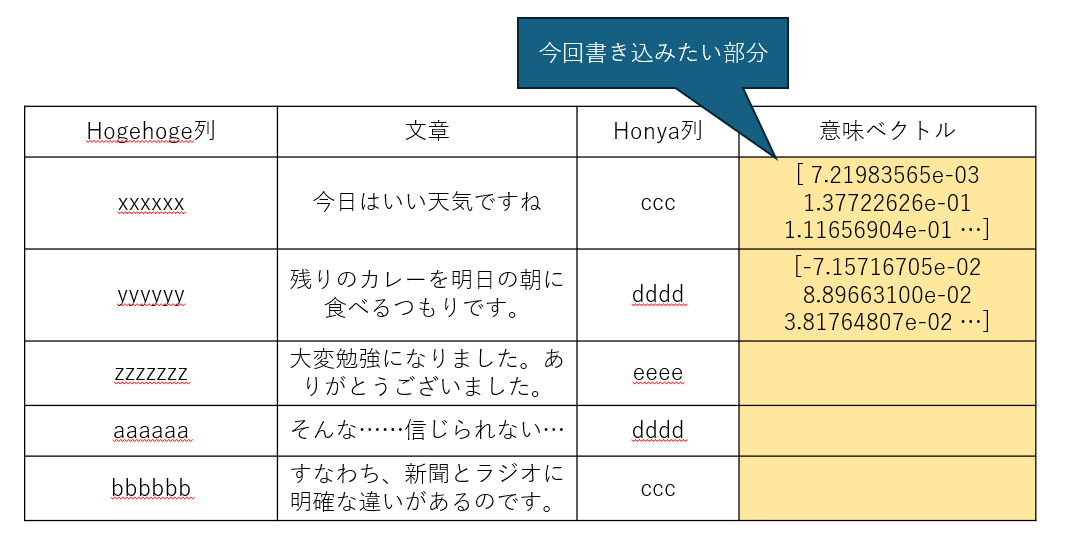
結論
Pythonの「Sentence Transformers」を使用します。
Sentence Transformersでは事前学習済みの深層学習モデルが用意されているので、その中でも日本語に対応しており、軽量・高速なモデル「all-MiniLM-L6-v2」を利用しました。
やったこと
■ 事前準備
- CSVファイル(import.csv)とPythonファイル(test.py)を同階層に配置する
- import.csvの「文章」列にデータを入れておきます。
- ライブラリは「pandas」「sentence-transformers」の二つを使用します。インストールしていない場合はコマンドプロンプトなどで以下コマンドを打ち、インストールしておきます。
pip install -U sentence-transformers
pip install -U pandas■ test.pyのコード
下記のコードで動きました。ほぼすべてAIに作ってもらいました。
import pandas as pd
import json
from sentence_transformers import SentenceTransformer
# === 設定 ===
input_csv = "import.csv" # 読み込むCSV
output_csv = "import.csv" # 上書き保存する場合は同じファイル名
summary_col = "文章" # 入力となる文章の列名
vector_col = "意味ベクトル" # ベクトルを格納する列名
encoding = "utf-8-sig" # 文字コード
# === CSV 読み込み ===
df = pd.read_csv(input_csv, encoding=encoding)
# 入出力列のチェック
if summary_col not in df.columns:
raise ValueError(f"CSVに『{summary_col}』列がありません。列名を確認してください。")
if vector_col not in df.columns:
df[vector_col] = None
# 欠損や空文字の置換処理
texts = df[summary_col].fillna("").astype(str).tolist()
# === SentenceTransformerの処理 ===
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(texts, batch_size=64, show_progress_bar=True)
# === 結果をJSON配列として格納し、書き出し ===
df[vector_col] = [json.dumps(vec.tolist(), ensure_ascii=False) for vec in embeddings]
df.to_csv(output_csv, index=False, encoding=encoding)結論としては以上なのですが、AIが書いたコードということでどんなことをやってるのか自分の振り返り用に書き留めておきます。
コードの説明
「CSV読み込み」「CSV書き込み」は以下のコード。
# === CSV 読み込み ===
df = pd.read_csv(input_csv, encoding=encoding)
# (中略)
# === 書き出し(上書き)===
df.to_csv(output_csv, index=False, encoding=encoding)入力時は.read_csvを用い、pandasのデータフレーム(df)としてCSVファイルを読み込みます。
出力時は.to_csvを用い、CSVファイルにdf全体を流し込んでいます。
encodingは「設定」で記載した文字コード、出力時のindex=Falseは、pandasのデータフレームで1列目に付与されるインデックス番号を除いて出力するための記述です。
入力データをチェック・整形する
all-MiniLM-L6-v2へデータを渡す前に、CSVから取り込んだデータが正しいかチェックし、場合によっては置換などの処理をおこないます。
# 『文章』列があるかチェック(ない場合は例外エラーを出して終了)
if summary_col not in df.columns:
raise ValueError(f"CSVに『{summary_col}』列がありません。列名を確認してください。")
# 『意味ベクトル』列があるかチェック(ない場合は空で作成)
if vector_col not in df.columns:
df[vector_col] = None
# 欠損や空文字は除外して扱う(その行は空リストを入れる)
texts = df[summary_col].fillna("").astype(str).tolist()一部について簡単に説明します。
raise ValueError(・・・)- summary_col not in df.columns の場合、すなわち「文章」列が存在しない場合)は明示的に例外を発生させてその場で処理を中断させます
texts = df[summary_col].fillna("").astype(str).tolist()- ① データフレームの中の「文章」列をシリーズとして取り出し(df[summary_col])
- ② NaN(欠損値)を 空文字に置換します※(.fillna(“”))
- ③ 「文章列」の中身のデータ型をすべて文字列に置換し(.astype(str))
- ④ さらに全体のデータ型をpandasのシリーズから通常のPythonのリストに変換する※(.tolist())
- ⑤ ④までの結果を「texts」に格納する
- ※いずれもSentence Transformersでうまく受け取れるようにするため。
Sentence Transformersへデータ受け渡し
# === SentenceTransformerの処理 ===
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(texts, batch_size=64, show_progress_bar=True)Sentence Transformersのモデルは以下のページ参照。
参考:https://huggingface.co/models?library=sentence-transformers&sort=downloads
今回は「all-MiniLM-L6-v2」をモデルとして使用しています。後述しますが、日本語の場合は他のモデルの方が望ましい結果が出ることもあるようです。
Sentence Transformersの使い方はall-MiniLM-L6-v2のページにUsageとして載っているので、そちらの通りにモデルを読み込み、文章の埋め込み(英語でembedding、つまり意味ベクトル化みたいな処理)をします。
「texts」は前段階で整形済みのデータですね。
「batch_size=64」はバッチ処理を実施するという意味らしい。調べたところ、(ふわっとした表現になりますが)モデルに渡すデータは通常1つずつですが、バッチサイズを指定してその数値(今回は64個)ごとに一気に渡すことで、モデルを呼び出す回数(=オーバーヘッド)を減らしたりCPU/GPUを効率的に活用したりできるとのこと。
つまり高効率で処理するためのデータの渡し方、みたいな理解で良さそうです。
変換後の意味ベクトルはembeddingに格納されます。この時点でのembeddingのデータ型はNumPy配列のリスト(ndarray)。
出力データ(意味ベクトル)を整形し、dfに格納
意味ベクトル化まで完了したので、CSVに出力できるようにデータを整形してから、データフレームの「意味ベクトル」列に追加します。
df[vector_col] = [json.dumps(vec.tolist(), ensure_ascii=False) for vec in embeddings]AIは1行で生成してくれましたが、意味としては以下でも同じ。
vectors_json = []
for vec in embeddings:
json_str = json.dumps(vec.tolist(), ensure_ascii=False)
vectors_json.append(json_str)
df[vector_col] = vectors_jsonまずembeddingのそれぞれの要素を取り出してvecに格納します。
この時点でvecのデータ型はnumpy配列ですが、そのままではCSVがうまく受け取れません。
そのためnumpy配列をPythonのリスト形式に変換し(vec.tolist())→その後、JSON形式に変換します(json.dumps(・・・)。
(numpy配列を直接JSON配列に変換することはできないので、一旦Pythonのリストを経由している)
またそのまま出力すると日本語を含むUnicode文字列は \uXXXX に変換されてしまうらしいので、それを防ぐために「ensure_ascii=False」を付与します。
参考:[Python] json.dumps()で日本語が\uXXXXになるときの対処法
全ての行の整形が完了したらdfの「意味ベクトル」列に格納します。
あとははじめに見た通り、下記コードでdf全体をCSVファイルに流し込んで完了です。
# === 書き出し(上書き)===
df.to_csv(input_csv, index=False, encoding=encoding)今回は特に設定していませんが、必要に応じて最後に処理件数(csvの行数)などを表示してもいいかもしれません。
Sentence Transformersの日本語向けモデルについて
おまけ。今回は軽量であることを優先して「all-MiniLM-L6-v2」モデルを利用しました。
当然ながらモデルによって同じ文章でも意味ベクトルが異なるため、文章が日本語のみの場合は日本語を対象としたモデルを選んだ方が望ましい結果を得られるかと思います。
この点の詳細は下記サイト内の「日本語モデルの比較実験」項目が参考になりそうなのでリンクを掲載させていただきます。
参考:PythonのSentenceTransformerを用いた文章類似度比較
Hugging faseでも言語別にフィルタをかけたり、ダウンロード数などを確認したりすることができます。
まだ「all-MiniLM-L6-v2」以外を使ったことがないので、ツール自体が動くようになったらモデルについても比較・選定をしてみたいところです。
おわりです。